What is this project about?
Imagine you're trying to navigate through a slippery ice rink to reach the other side, but every step you take has a chance of sending you sliding in an unintended direction. How would you learn the safest and most efficient path when you can't be sure your movements will go as planned?
This project demonstrates how an AI agent learns to navigate through uncertain environments using Q-learning, a fundamental reinforcement learning algorithm. The agent must find optimal paths to its goal while dealing with movement uncertainty, obstacles, and hazards - just like navigating through real-world situations where things don't always go according to plan.
See the Agent in Action
Q-learning agent adapting its navigation strategy in a stochastic environment
The Navigation Challenge
Stochastic Environment
Unlike deterministic environments where actions always produce predictable outcomes, this agent operates in a stochastic world. When it tries to move in one direction, there's only an 80-90% chance it will actually go that way - the rest of the time, it might slip or drift in a different direction.
Learning Under Uncertainty
The agent must learn to deal with this uncertainty by developing robust strategies. It can't just memorize a fixed path - it needs to understand the probability distributions of its actions and adapt its policy to handle the unpredictability of movement.
Obstacle Avoidance
The environment contains obstacles and hazards that the agent must learn to avoid. Since movement is uncertain, the agent must be extra careful near dangerous areas, developing conservative strategies that account for the possibility of unintended movements.
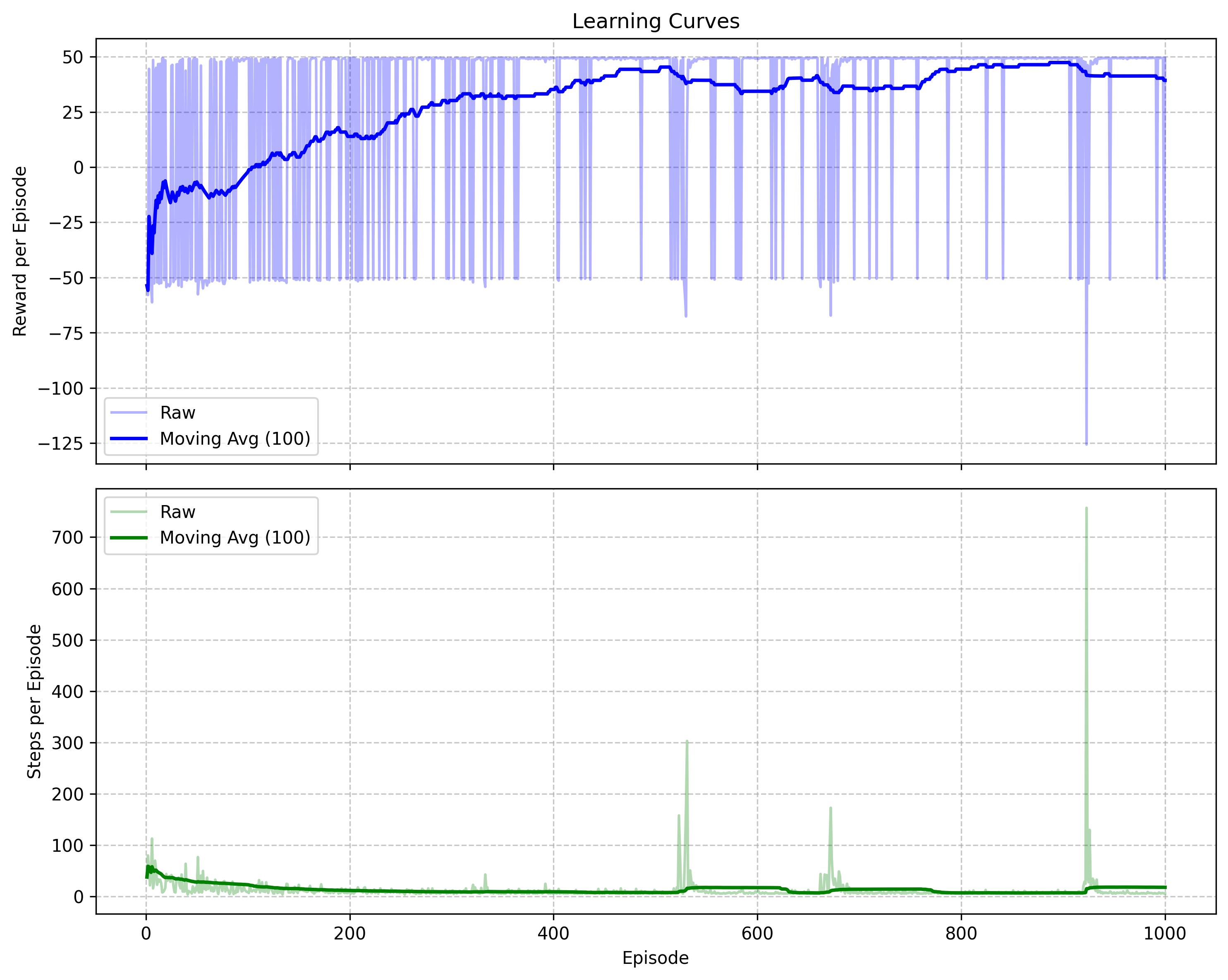 Reward accumulation and episode length over training episodes
Reward accumulation and episode length over training episodes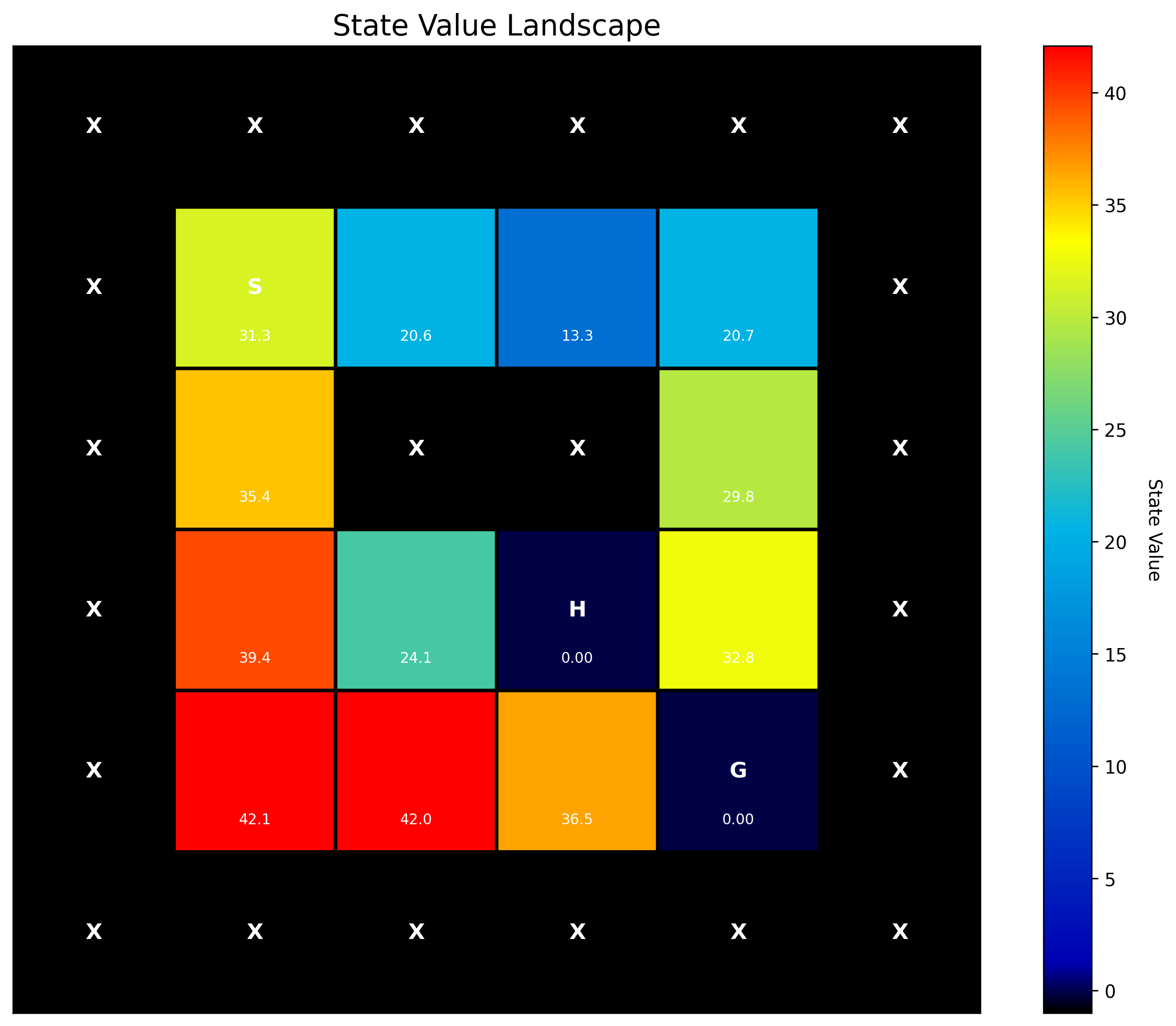 Visual representation of the agent's learned state values
Visual representation of the agent's learned state values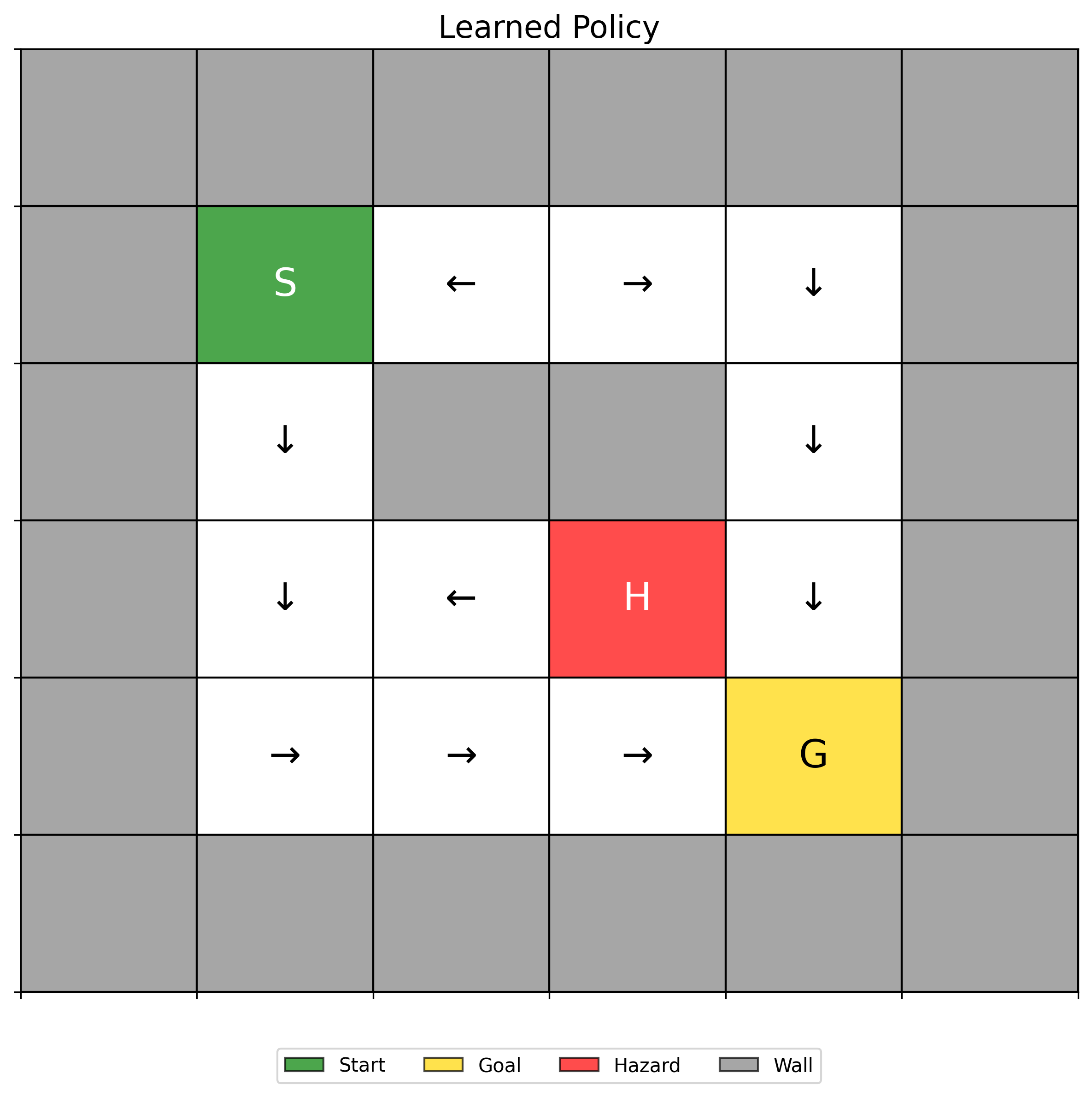 Arrows showing preferred actions for each grid position
Arrows showing preferred actions for each grid position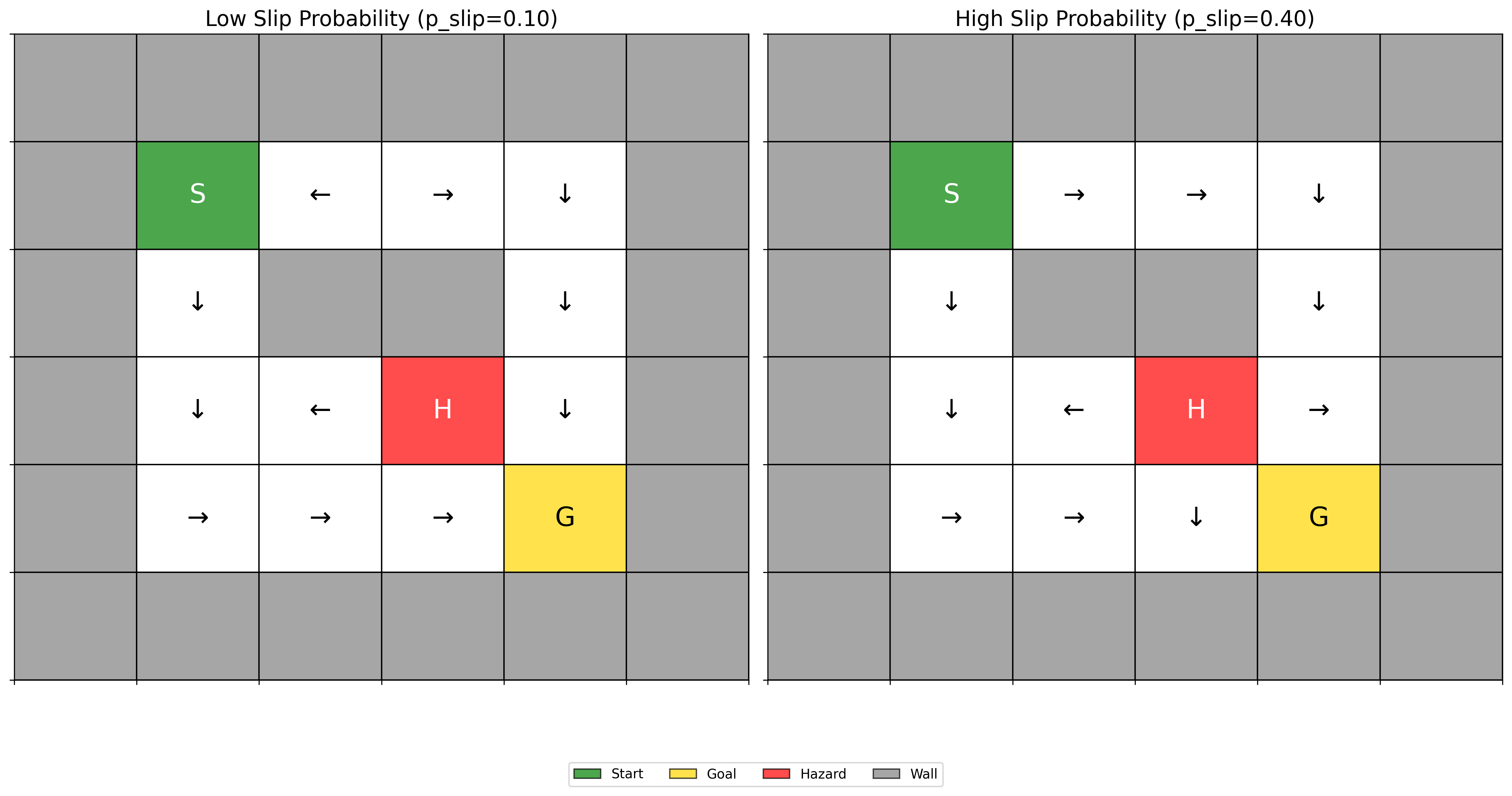 Side-by-side visualization of strategies under different uncertainty levels
Side-by-side visualization of strategies under different uncertainty levels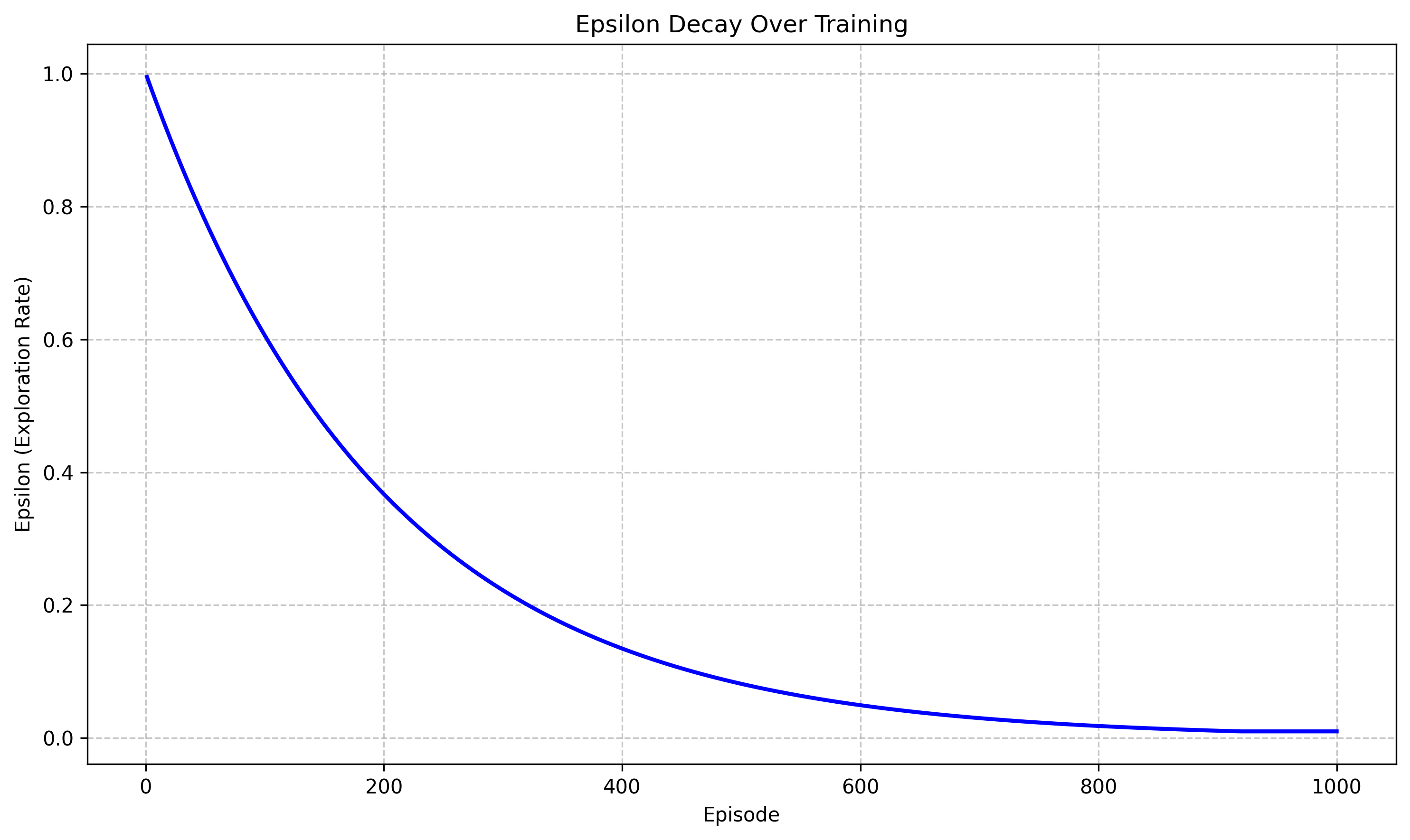 Visual tracking of exploration vs. exploitation balance
Visual tracking of exploration vs. exploitation balance